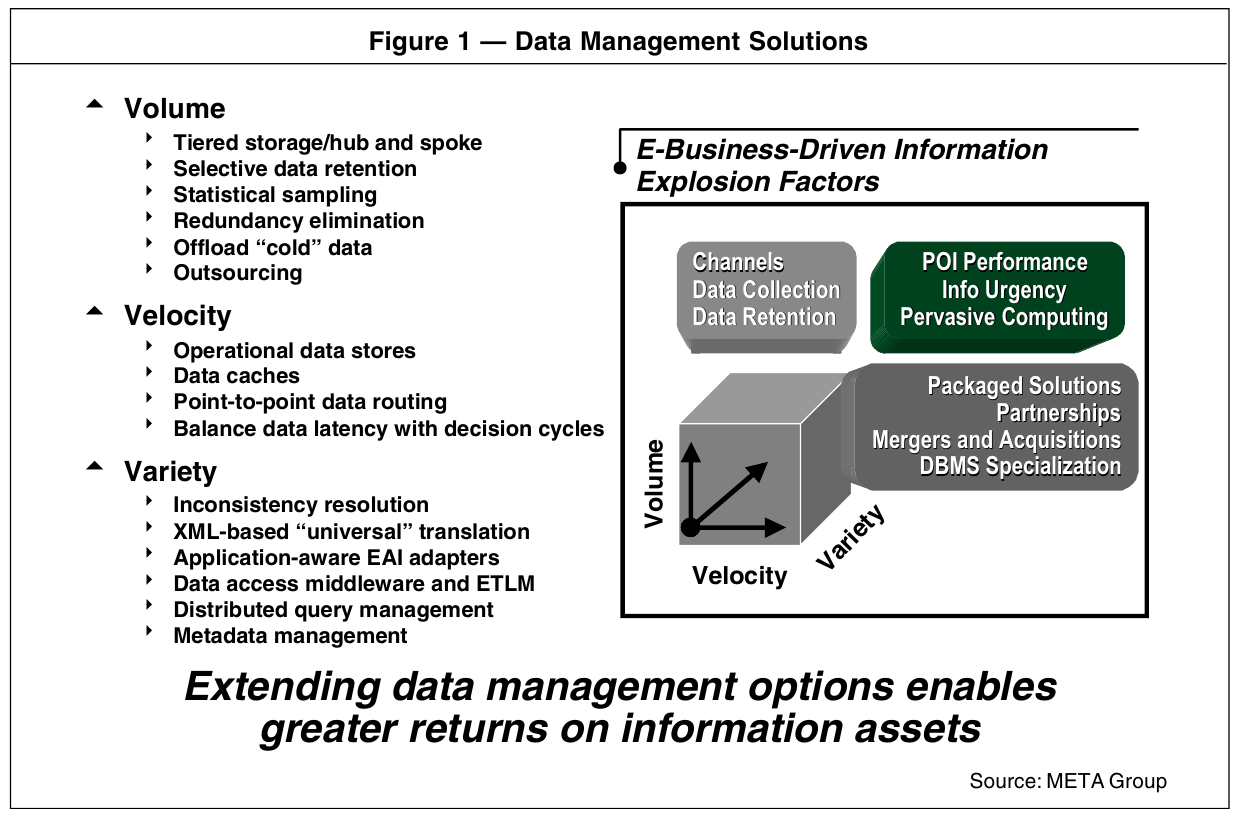
1. 아마존 SimpleDB의 데이터 모델용어와 관계형 데이터베이스(RDBMS)의 데이터 모델용어의 연결이 적절하지 않은 것은?
ㄱ. Domain - Table
ㄴ. Attribute - Column
ㄷ. Data Dictionary - Schema
ㄹ. Item - Record
2. 무공유(Shared Nothing) 클러스터와 공유 디스크(Shared Disk) 클러스터를 비교한 내용 중 옳지 않은 것은?
ㄱ. 무공유 클러스터에서 각 데이터베이스 인스턴스는 자신이 관리하는 데이터 파일을 자신의 로컬 디스크에 저장하며, 이 파일들은 노드 간에 공유하지 않는다.
ㄴ. 공유 디스크 클러스터는 노드 확장에 제한이 없으나, 무공유 디스크는 클러스터가 커지면 디스크 영역에서 병목현상이 발생한다.
ㄷ. 공유 디스크 클러스터의 경우 높은 수준의 폴트톨러런스(fault-tolerance)를 제공하므로 클러스터를 구성하는 노드 중 하나의 노드만 살아 있어도 서비스가 가능하다.
ㄹ. Oracle RAC(Real Application Cluster)를 제외한 대부분의 데이터베이스 클러스터가 무공유 방식을 채택하고 있다.
3. 다음 중 구글 파일 시스템(GFS)을 설계할 때 세웠던 가정으로 적절하지 않은 것은?
ㄱ. 높은 처리율보다 낮은 응답 지연시간이 중요하다.
ㄴ. 여러 클라이언트에서 동시에 동일한 파일에 데이터를 추가하는 경우를 고려한다.
ㄷ. 파일에 대한 쓰기 연산은 주로 순차적으로 일어나고, 파일에 대한 갱신은 드물게 이루어진다.
ㄹ. 저가형 서버로 구성된 환경으로 서버의 고장이 빈번히 발생할 수 있다고 가정한다.
4. GFS(Google File System)의 구동원리 중 옳지 않은 것은?
ㄱ. 청크(chunk)는 청크서버에 의해 생성/삭제 될 수 있으며, 유일한 식별자에 의해 구별된다.
ㄴ. GFS는 트리 구조가 아닌 해시 테이블 구조 등을 사용함으로써 메모리상에서 보다 효율적인 메타데이터의 처리를 지원한다.
ㄷ. GFS는 파일을 임의의 크기의 청크(chunk)들로 나누어 청크서버들에 분산/저장한다.
ㄹ. 클라이언트는 마스터로부터 읽고자 하는 파일의 청크(chunk)가 저장된 청크서버의 위치를 알아온 뒤, 직접 청크서버에 파일 데이터를 요청한다.
5. 분산 파일 시스템인 러스터(Luster)에 대한 설명 중 옳지 않은 것은?
ㄱ. 클러스터 파일 시스템(Cluster File Systems Inc.)에서 개발한 객체 기반 클러스터 파일 시스템이다.
ㄴ. 고속네트워크로 연결된 클라이언트 파일 시스템, 메타데이터 서버, 객체 저장서버들로 구성되어 있다.
ㄷ. 러스터는 파일의 메타 데이터와 파일 데이터에 대한 동시성 제어를 위해 별도의 잠금을 사용한다.
ㄹ. 객체 저장서버는 파일 시스템의 이름 공간과 파일에 대한 메타데이터를 관리한다.
6. Oracle RAC 데이터베이스 서버에 대한 다음의 설명 중 옳지 않은 것은?
ㄱ. Oracle RAC 데이터베이스 서버는 한 노드가 어떤 이유로 장애를 일으켰을 때 클러스터를 구성하는 노드 중 하나의 노드만 살아 있어도 서비스가 가능하다.
ㄴ. 추가 처리 성능이 필요하면 응용 프로그램이나 데이터베이스를 수정할 필요 없이 새 노드를 클러스터에 쉽게 추가할 수 있다.
ㄷ. 클러스터의 모든 노드는 데이터베이스의 모든 테이블에 차등하여 액세스하며, 특정 노드가 데이터를 '소유'하는 개념이 존재한다.
ㄹ. RAC는 표준화된 소규모(CPU 4개 미만) 저가형 상용 하드웨어의 클러스터에서도 고가의 SMP 시스템만큼 효율적으로 응용 프로그램을 실행함으로써 하드웨어 비용을 절감한다.
7. NoSQL에 대한 다음의 설명 중 옳지 않은 것은?
ㄱ. NoSQL은 Key와 Value의 형태로 자료를 저장하고, 빠르게 조회할 수 있는 자료 구조를 제공하는 저장소다.
ㄴ. 전통적인 RDBMS의 장점이라고 할 수 있는 복잡한 Join 연산 기능을 지원한다.
ㄷ. 스키마 없이 동작하며, 구조에 대한 정의 변경 없이 자유롭게 데이터베이스의 레코드에 필드를 추가할 수 있다.
ㄹ. 높은 수평적 확장성, 가용성, 성능을 제공한다.
8. 구글 Sawzall에 대한 설명 중 옳은 것은?
ㄱ. Sawzall은 MapReduce를 구체화한 스크립트 형태의 병렬 프로그래밍 언어다.
ㄴ. Sawzall은 사용자가 이해하기 쉬운 인터페이스를 제공하며, MapReduce 개발 생산성과는 관련성이 없다.
ㄷ. 오픈소스 프로젝트인 Pig나 하이브(Hive)의 개발 배경과 기본적인 개념은 Sawzallrhk dbtkgkek.
ㄹ. MapReduce에 대한 이해가 없으면 병렬 프로그래밍에 어려움이 있다.
9. MySQL에 대한 다음의 설명 중 옳지 않은 것은?
ㄱ. 특정한 하드웨어 및 소프으퉤어를 요구하지 않고 병렬 서버구조로 확장이 가능하다.
ㄴ. MySQL 운영 중에 노드를 추가/삭제가 가능하다.
ㄷ. MySQL 클러스터는 데이터의 가용성을 높이기 위해 데이터를 다른 노드에 복제시키며, 특정 노드에 장애가 발생하더라도 지속적인 데이터 서비스가 가능하다.
ㄹ. 클러스터에 참여하는 노드(SQL 노드, 데이터 노드, 매니저를 포함) 수는 255로 제한한다. 데이터 노드는 최대 48개까지만 가능하다.
10. MapReduce에 대한 설명 중 옳지 않은 것은?
ㄱ. 분할정복 방식으로 대용량 데이터를 병렬로 처리할 수 있는 프로그래밍 모델이다.
ㄴ. 맵과 리듀스라는 2개의 함수 구현으로 동작되는 시스템이다.
ㄷ. 정렬과 같은 작업은 맵리듀스 모델을 적용하여 처리하기에 매우 적합하다.
ㄹ. map 단계에서는 key와 value의 쌍들을 입력으로 받는다.
11. 다음 중 가상화 기술을 이용할 경우 얻을 수 있는 효과로 가장 부적절한 것은?
ㄱ. 수시로 변화하는 가상머신의 자원 요구량에 맞추어 전체 시스템의 자원을 재배치함으로써 자원 할당의 유연성을 증가시킨다.
ㄴ. 가상머신에서 수행중인 애플리케이션의 장애가 다른 가상머신에는 전혀 영향을 미치지 않는다.
ㄷ. 다양한 운영체제나 운영환경에서 테스트가 필요한 경우, 새로운 서버를 추가하지 않아도 테스트 환경을 구성할 수 있다.
ㄹ. 마이그레이션(migration) 기능을 이용할 경우 운영 중인 가상머신을 중지하고, 가상머신을 다른 물리적인 서버로 이동시킬 수 있다.
12. Hadoop Architecture에 대한 설명 중 옳지 않은 것은?
ㄱ. JobTracker는 MapReduce 시스템의 마스터이고, TaskTracker는 워커 데몬이다.
ㄴ. TaskTracker는 JobTracker에게 3초에 한 번씩 주기적으로 하트비트(Heartbeat)를 보내 살아 있다는 것을 알린다.
ㄷ. 데몬 관점에서 하둡은 2개의 구성요소를 가지고 있다.
ㄹ. 네임노드(NameNode)와 데이터노드(DataNode)는 분산 파일 시스템의 데몬들이다.
13. SQL on Hadoop 기술에 대한 설명 중 옳지 않은 것은?
ㄱ. 하둡에 저장된 대용량 데이터를 대화형식의 SQL질의를 통해서 처리하고 분석하는 기술이다.
ㄴ. 임팔라는 하둡과 Hbase에 저장된 데이터를 대상으로 SQL질의를 할 수 있다.
ㄷ. 호튼웍스에서 개발한 아파치 스팅거(Stinger)는 하이브 코드를 최대한 이용하여 성능을 개선하는 방식으로 개발하였다.
ㄹ. SQL on Hadoop 원조 기술은 구글에서 개발한 빅테이블이다.
14. 다음 중 하둡의 성능과 관련된 설명으로 옳지 않은 것은?
ㄱ. 맵리듀스 작업에서 sort 작업은 데이터가 커지더라도 처리시간이 크게 증가하지 않는다.
ㄴ. 하둡 클러스터를 구성하는 서버의 수를 늘림으로써 처리 시간을 줄일 수 있는 것은 아니다.
ㄷ. 플랫폼이 선형 확장성을 가지고 있다면 처리 속도를 개선할 수 있다.
ㄹ. 맵리듀스의 sort는 map에서 reduce로 넘어가는 과정에서 항상 발생하는 프로세스이다.
15. 병렬 쿼리 시스템 중 하나인 아파치 Pig에 대한 설명으로 옳은 것은?
ㄱ. 야후에서 개발한 데이터 저장을 위한 언어이며, 아직 오픈소스 프로젝트화되지 않았다.
ㄴ. Hadoop MapReduce 위에서 동작하는 구체화된 병렬 처리 언어이다.
ㄷ. Pig는 맵리듀스의 중복된 알고리즘 개발, 코드 공유의 어려움 등의 요구사항을 해결하기 위해 정의된 언어이다.
ㄹ. 아파치 Pig를 이용하면 MapReduce를 이용할 때 보다 프로그래밍해야 할 코드 라인의 수는 줄지 않지만 데이터 처리 속도가 매우 빨라진다.
16. 클라우드 컴퓨팅 기반이 되는 인프라 기술인 가상화에 대한 설명 중 옳지 않은 것은?
ㄱ. 최근에는 CPU 제조업체에서도 하드웨어에서 가상화 기술을 지원하는 등 새로운 가상화 방법이 계속 나오고 있기 때문에 서버 가상화 기술을 정확하게 분류하기는 힘들다.
ㄴ. 컨테이너 기반 가상화 방식에서 가상화를 지원하는 계층을 하이퍼바이저라고 한다.
ㄷ. 서버 가상화는 물리적인 서버와 운영체제 사이에 적절한 계층을 추가해 서버를 사용하는 사용자에게 물리적인 자원은 숨기고 논리적인 자원만을 보여주는 기술이다.
ㄹ. 완전가상화는 어떠한 운영 체제라도 수정하지 않은 채 설치가 가능하다.
17. 하이퍼바이저 기반의 가상화와 컨테이너 기반 가상화를 비교한 다음의 내용 중 옳지 않은 것은?
ㄱ. 하이퍼바이저 기반 가상화는 가상머신 내에서 완전한 하드웨어 독립성을 가지며, 컨테이너 기반 가상화는 호스트 OS를 사용한다.
ㄴ. 하이퍼바이저 기반 가상화는 높은 오버헤드를 발생시키는 반면, 컨테이너 기반 가상화는 오버헤드가 거의 없다.
ㄷ. 컨테이너 기반 가상화는 공통 소프트웨어에 의한 중앙 집중식 관리 구조를 가지며, 하이퍼 바이저 기반 가상화는 가상머신별로 별도로 관리되는 구조를 가진다.
ㄹ. Xen과 VMware ESX는 컨테이너 기반 가상화의 대표 제품이다.
18. 다음 중 MySQL에 관한 설명으로 옳지 않은 것은?
ㄱ. 장애가 발생했던 노드가 복구되어 클러스터에 투입된 경우에도 기존 데이터와 변경된 데이터에 대한 동기화 작업이 자동으로 수행된다.
ㄴ. MySQL의 구성요소 중 MySQL 노드는 클러스터를 관리하는 노드로 클러스터 시작과 재구성 시에만 관여한다.
ㄷ. 클러스터에 참여하는 노드(SQL 노드, 데이터 노드, 매니저를 포함) 수는 255로 제한되며, 데이터 노드는 최대 48개까지만 가능하다.
ㄹ. MySQL 클러스터는 비공유형으로서 메모리 기반 데이터베이스의 클러스터링을 지원한다.
19. 호스트 컴퓨터에서 다수의 운영 체제를 동시에 실행하기 위한 논리적 플랫폼인 하이퍼바이저(Hypervisor)에 대한 설명으로 옳지 않은 것은?
ㄱ. 일반적으로 가상머신(Virtual machine)을 하이퍼바이저라고 할 수 있다.
ㄴ. 물리적 서버 위에 존재하는 가상화 레이어를 통해 운영체제를 수행하는데 필요한 하드웨어 환경을 가상으로 만들어 준다.
ㄷ. 하이퍼바이저를 통해 사용자는 추가 하드웨어 구입 없이 새로운 운영체제의 설치, 애플리케이션의 테스팅 및 업그레이드를 동일한 물리적 서버에서 동시에 수행할 수 있다.
ㄹ. 하이퍼바이저는 하드웨어 환경 에뮬레이션(emulation)을 수행하지만 소프트웨어 스택 보존의 기능은 수행하지 못한다.
20. 다음의 데이터베이스 클러스터에 대한 설명 중 옳지 않은 설명은 무엇인가?
ㄱ. Oracle RAC 데이터베이스 서버는 공유 클러스터이며, 별도의 폴트톨러런스 기능은 제공하지 않는다
ㄴ. 데이터베이스 파티셔닝을 구현하면 성능의 선형적인 증가 효과를 볼 수 있다.
ㄷ. MS SQL Server는 연합 데이터베이스 형태이며, Active-Standby 방법의 페일오버(failover) 메커니즘을 제공한다.
ㄹ. Oracle RAC 데이터베이스 서버에서 클러스터가 커지면 디스크 영역의 병목현상이 발생할 수도 있다.
'ADP (데이터분석전문가) > ADP 필기 기출문제' 카테고리의 다른 글
| [ADP] 필기 기출문제 - 2과목 1장: 데이터 처리 프로세스 (0) | 2024.02.20 |
|---|---|
| [ADP] 필기 기출문제 - 1과목: 데이터의 이해 (2) | 2024.02.20 |